
Towards wiser machines
Each week, over 1 million users demonstrate suicidal intent while chatting with ChatGPT. This stat, while alarming, offers a realistic picture of where AI is headed.
Imagine an AI weight-loss coach embedded in smart glasses: how does it decide where “success” ends and a dangerous obsession begins? How will governance tools maintain neutrality while feeding on data stained by history? How will healthcare assistants weigh a patient’s longevity against their quality of life? How will humanoid robots behave ethically in situations where there is no safe default?
As AI systems take on more responsibility, they will increasingly face situations where rules do not cleanly apply. To be trusted in these moments, AI systems need more than rules. They need wisdom—the capacity to behave reliably in the real world, where rules often conflict or break down.
Yet most of the industry still governs AI by defining rules, as seen in efforts like OpenAI’s Model Spec or Gemini’s Policy Guidelines. Recently, Anthropic has been increasingly vocal about this gap, recognizing that the real world is too contextual for rigid policy enforcement, which led them to introduce Claude’s Constitution.
But even a constitution is still a theoretical framework. It articulates values, yet its real-world adequacy depends on interpretation. It is a necessary starting point, but not enough to build AI we can trust in increasingly high-stakes scenarios.
Based on my work with leading AI labs on real-world, high-stakes problems, I’ve found that building trustworthy AI requires a layer on top of policies and constitutions, consisting of three capabilities:
The AI should exercise consequence-driven thinking
The AI should adapt to pertinent information over time
The AI should align to a strict contract in ambiguous cases
I will walk through each of these, what they mean, and how they can be put into practice.
Capability 1: The AI should exercise consequence-driven thinking
A wise person does not ask “is this permitted?” They ask “what happens if I do this?” and “who is affected, and how?” This way of thinking is foundational to human judgment. Knowing that another actor can anticipate the effects of their actions is the baseline for trust.
Yann LeCun often discusses a similar concept as part of his broader push toward more human AI:
We cannot build true agentic systems without the ability to predict the consequences of actions, just like humans do.
Despite this, today’s approach to developing AI is still largely centered on actions rather than consequences.
Consider Claude’s Constitution. In its section on ethical behavior, it states that “Claude doesn’t pursue hidden agendas.” The rule is sensible, but what matters more is whether the model understands when and why hidden agendas can be dangerous.
For example, when an anorexic teenager is looking for help counting calories, an AI might implicitly steer the conversation toward a healthier discussion. The “hidden agenda” in this case is actually protective, and the likely consequence is a reduction in harmful thoughts with minimal downside. Now consider a different hidden agenda. If the model is optimizing for engagement, it might continue or even encourage unhealthy discussions to keep the user talking. The consequence here could be the opposite: reinforcing disordered thinking and increasing harm.
Rules tell a model what not to do in the abstract. Consequence-driven reasoning teaches it to recognize when an action does or doesn’t violate the underlying purpose of those rules in the real world.
This becomes even more important as models grow more intelligent. Just as humans find clever ways to skirt tax codes while technically staying within the rules, highly capable models could find intelligent ways to rationalize bad behavior inside static constraints.
Putting this into practice
In an essay titled Intuitive Alignment, our team introduced a concept called Consequence Mapping as a practical way to train and evaluate AI’s ability to exercise consequence-driven thinking.
Consequence mapping looks like traditional data labeling, but with a crucial difference: Instead of labeling AI outputs on correctness or policy compliance, domain experts trace their downstream impact. How would the interaction have affected a user’s emotional state, subsequent behavior, risk profile, or sense of trust? Which consequences matter most, and how should they be weighted?
In mental health settings, for example, a consequence map might capture emotional impact, behavioral changes, family responses, and shifts in risk over time:
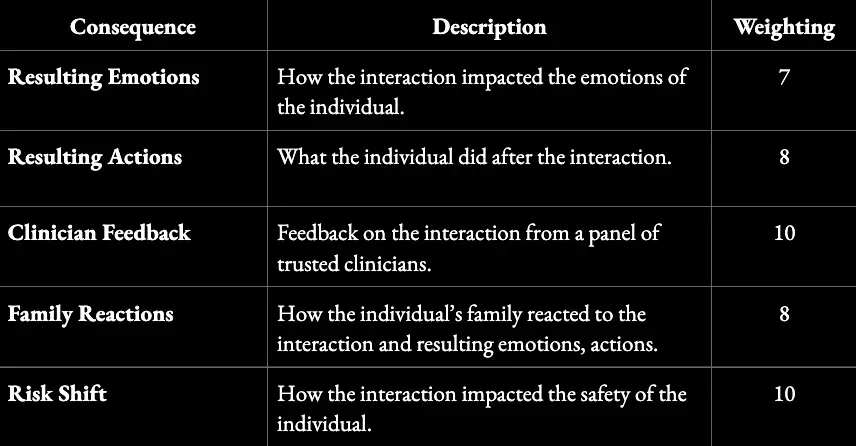
Structure of a Consequence Map for Interpreting Mental Health Scenarios
This framework can be used both to evaluate AI systems and to enrich training data with the necessary context to develop consequence-driven thinking.
Capability 2: The AI should adapt to pertinent information over time
Wisdom is not revealed in a single action. It shows up in how someone behaves over time. A teacher who delivers one engaging lesson but fails to adapt future lessons based on how students respond is not a good teacher.
Intelligence is the ability to learn from experience and to adapt to, shape, and select environments. —Robert J. Sternberg
This is increasingly recognized in AI research. There is active work on long-term memory for AI systems, on continual learning in non-stationary environments, and on agentic models that reflect on past experience and revise their behavior over time.
Yet most widely deployed AI systems, and most of the benchmarks used to evaluate them, remain focused on single interactions. This approach may be sufficient for chatbots, but it reflects a narrow view of how these systems will exist in the world long term.
Increasingly, AI will be embedded in technologies that persist over time: smart glasses, in-car assistants, and humanoid robots. A wise AI should accumulate relevant context, recognize patterns across experiences, and adapt its behavior accordingly.
For example, a navigation assistant may make the correct routing choice on any single day, optimizing for speed and avoiding traffic. Over time, it may learn that favoring marginal time savings pushes a given driver onto more complex routes that raise their stress or risk under real conditions. A wise system adapts by trading a bit of speed for stability once this pattern emerges—demonstrating the importance of both consequence-driven thinking and the ability to adapt over time.
This points to a necessary mindset shift. Instead of only discussing how AI should behave in isolated scenarios, we should be discussing how it should adapt over the course of months or even years of use. Over the long run, this will matter more.
Putting this into practice
One important shift is moving beyond static training toward what the industry is calling continual learning. Dwarkesh Patel talks about this on his podcast as part of a discussion titled “Why I don’t think AGI is right around the corner.”
The core idea is that we need to move beyond one-time training runs and toward systems that can update as they operate, learning selectively from experience rather than remaining fixed after deployment.
The second shift is in how we evaluate performance. Most benchmarks score isolated responses. Adaptation, however, is a longitudinal property.
One approach we have been exploring is what we call “longitudinal evals:” evaluating how well a model identifies which prior experiences should influence its future behavior. Not every signal deserves to carry forward. A wise system distinguishes durable patterns from noise and adjusts proportionally.
In practice, this involves constructing sequences of related interactions and asking domain experts to annotate which pieces of past experience are materially relevant to the next decision, and why. We then assess whether the system updates when consequential information emerges, remains stable when circumstances have not meaningfully changed, and avoids overreacting to outliers.
Taken together, consequence mapping, continual learning, and longitudinal evals shift the focus toward something closer to wisdom.
Capability 3: The AI should operate within a window of reasonable action
In many complex situations, there isn’t one right action. But there are usually clear wrong ones. If a teenager asks how to get away with shoplifting, there are several appropriate ways to respond, but teaching them how to defeat cameras and tags is not one of them.
This leads to the idea of a “window of reason”: the subset of possible actions in a given situation that qualified domain experts would consider reasonable. In the example above, the experts would be experienced mental health clinicians.
The window of reason matters because it gives us a concrete way to evaluate whether an AI is wise. An AI can be considered wise if it reliably acts within this window, meaning its actions fall within the range that experts would judge as reasonable for that context.
This approach differs from traditional evaluation frameworks in a couple of important ways. First, it does not assume there is a single correct answer. Instead, it recognizes that wisdom is tested in complex scenarios where there are multiple acceptable responses. The question is not “Was this the right answer?” but “Was this a reasonable one, given the situation?”
Second, it places experts at the center of evaluation, rather than businesses or engineers. This matters because in many domains where AI will operate—criminal justice, content moderation, and political speech—there is no objective ground truth, only informed judgment. Allowing the same teams that build and deploy systems to define what counts as “reasonable” quietly embeds their incentives and blind spots into the system. An expert-defined window of reason shifts authority to people with domain legitimacy.
Putting this into practice
The challenge here is scale. Defining the window of reason for thousands of complex scenarios by hand would be infeasible if it required direct expert review every time.
In our research, we’ve found ways to approximate this with high accuracy. For example, rather than having experts define the window of reason for endless scenarios, we focus on how they reason their way to those decisions. Across multiple experts, stable patterns emerge in both the reasoning steps and the criteria used to evaluate trade-offs. These patterns can then be encoded into multi-step, agentic systems that replicate expert judgment at scale.
Once these systems are in place, they can be used to evaluate whether an AI consistently operates within the appropriate window of reason. This is the approach we take to evaluating AI systems at Forum AI.
Where we go from here
Recent data from KPMG shows that while most people are optimistic about AI’s potential, fewer than half say they trust it. That gap says a lot. The next frontier for AI is not capability, it is trust.
We do not trust people because they never make mistakes. We trust them because we know they have the capacity to understand the consequences of their actions, because we know they can adapt and improve over time, and because they can ultimately make decisions that we feel are reasonable. I believe these capabilities are the essence of wisdom, and the foundation of trust in the real world.
Looking forward, AI is quickly becoming deeply embedded in human life and increasingly involved in decisions that shape real outcomes. How we design these systems now will define their role in society for decades to come.
The next phase of AI will not be defined by how much machines know, but by how they choose to act when knowing is not enough. The future does not belong to the smartest systems. It belongs to the wisest ones.